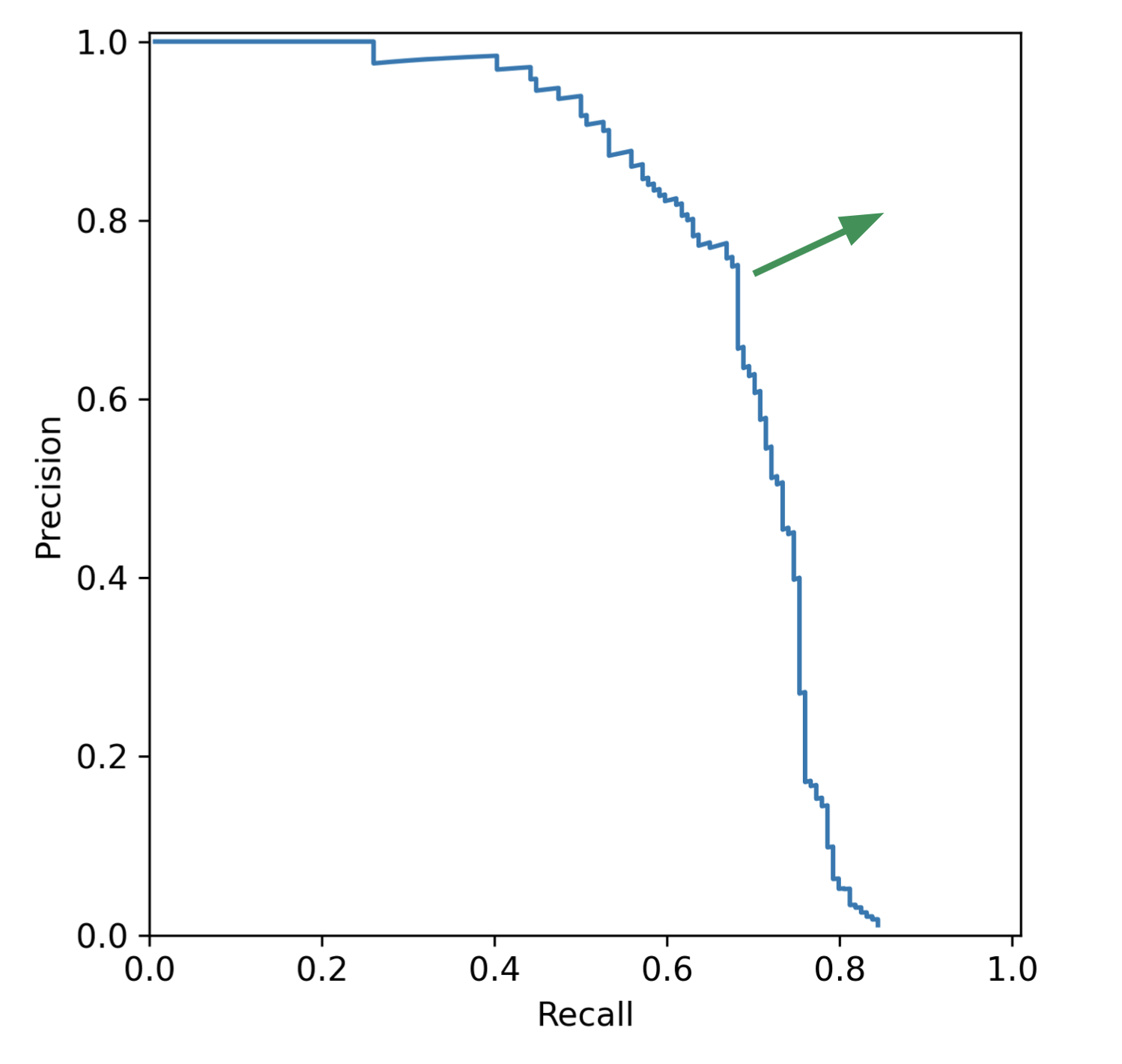
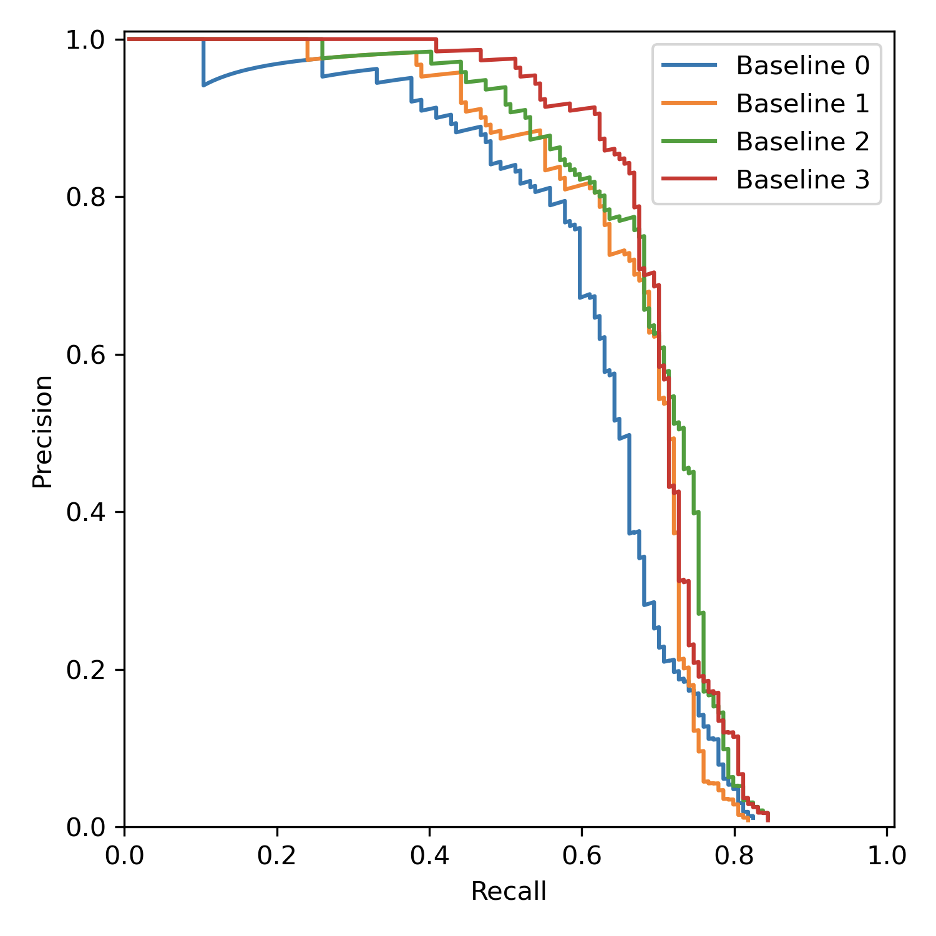
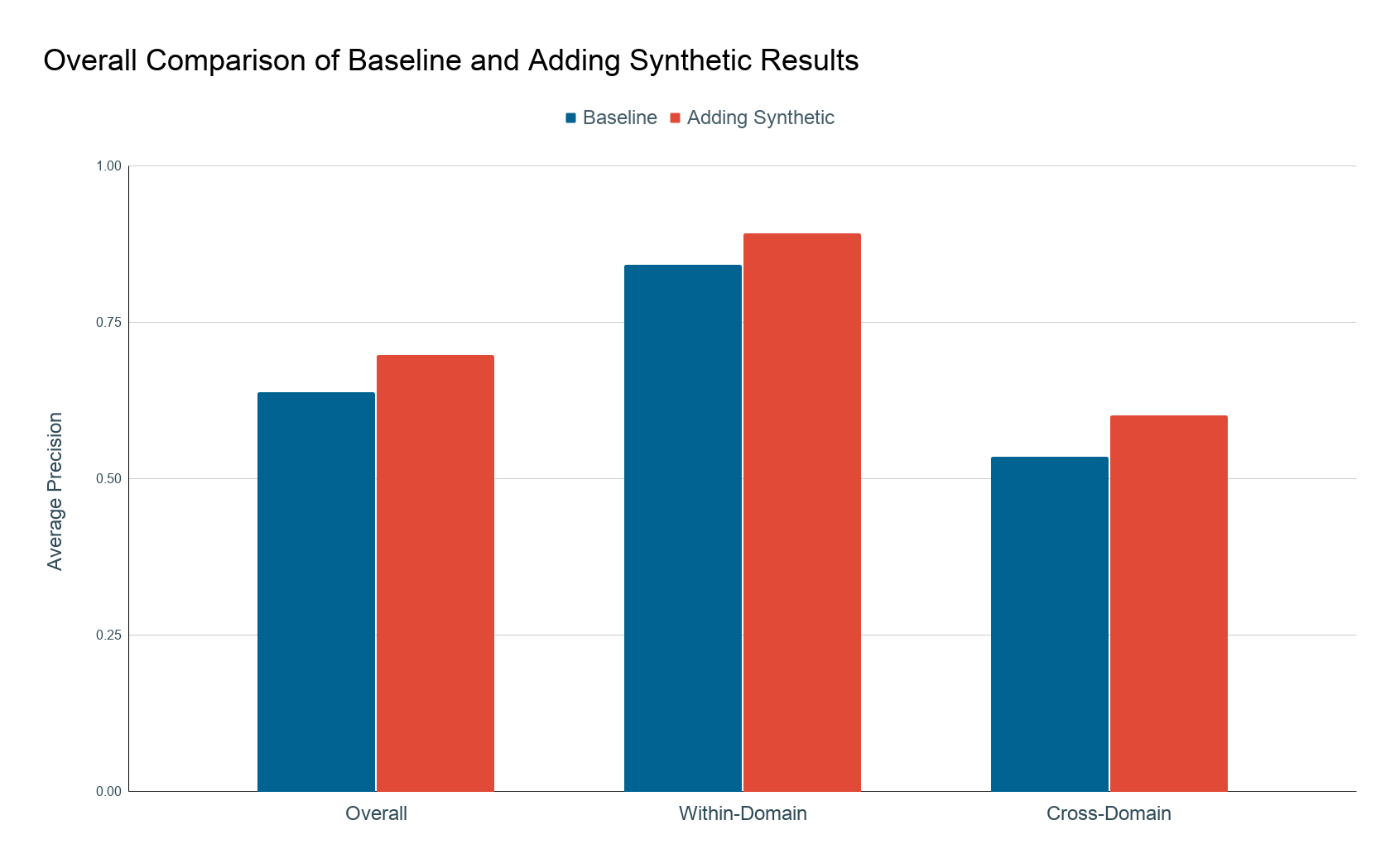
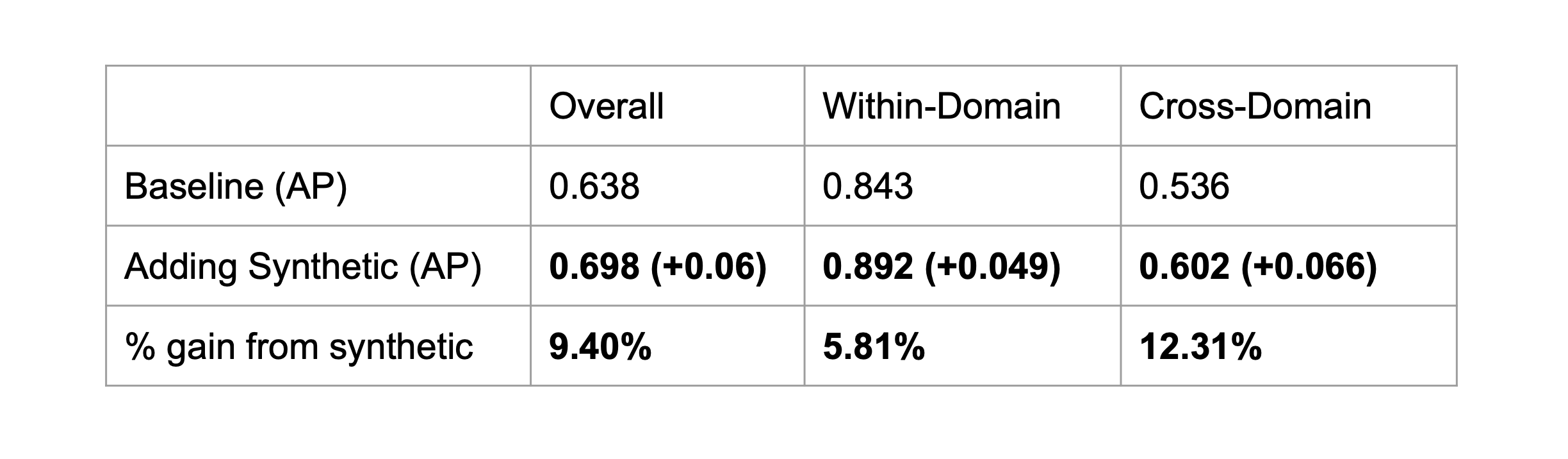
Motivation
Energy Access Planning
Access to electricity is correlated with improvements in income, education, maternal mortality, and gender equality. Around 1.2 billion people worldwide do not have electricity in their homes, many of them located in Subsaharan Africa and Asia. Information on the location and characteristics of energy infrastructure comprising generation, transmission, and end-use consumption can inform policy makers in energy access planning and is critical to efficiently deploying energy resources. Such information will allow energy developers to understand how best serve the electricity needs of communities without access to electricity through either power grid extensions, micro/mini grids, or off-grid solutions.
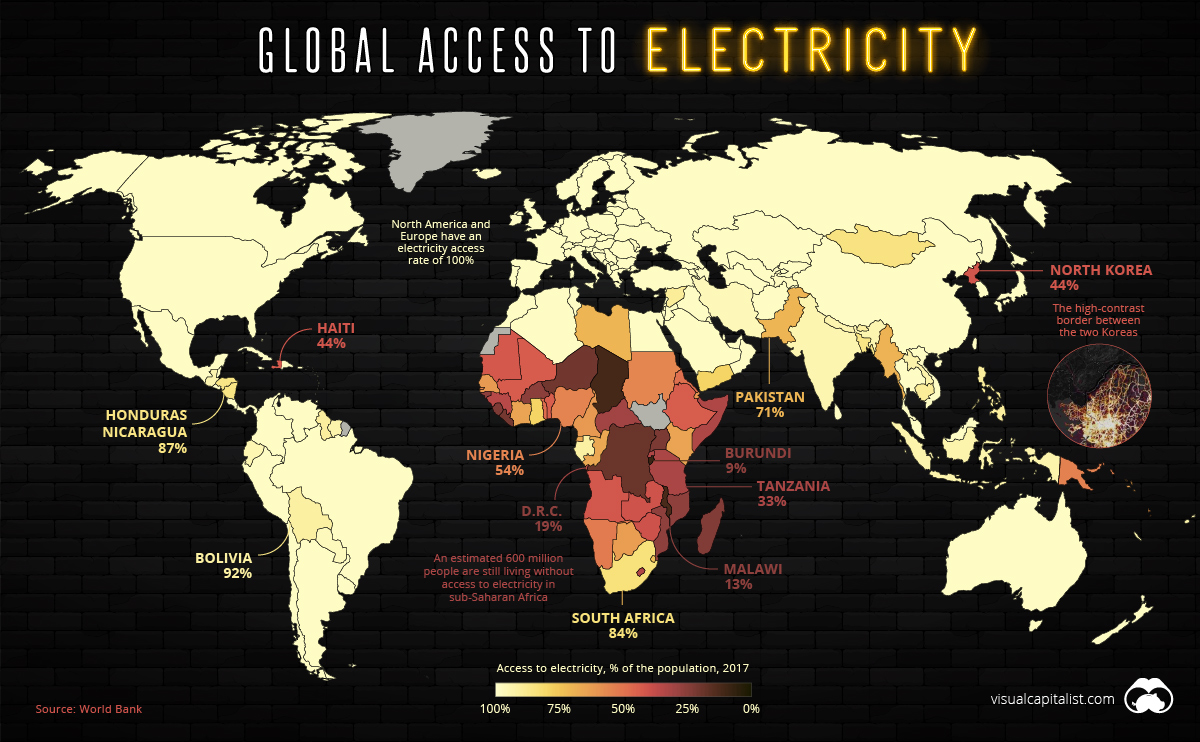
However, energy data for developers is often outdated, incomplete, or inaccessible. This is a common issue for NGO’s and other developers of distributed energy resources (DER) and microgrids who are looking to provide additional electricity access.
One potential solution to this lack of energy infrastructure data is to automate the process of mapping energy infrastructure using deep learning in satellite imagery. Using deep learning, we can feed an overhead image to a model and make predictions about the contents or characteristics of the region photographed in the image. Using this tool, the resulting information on energy infrastructure can then help inform energy access planning, such as deciding the most cost-effective option among distributed generation, micro-grids, or grid extension strategies for electrification.
Object Detection
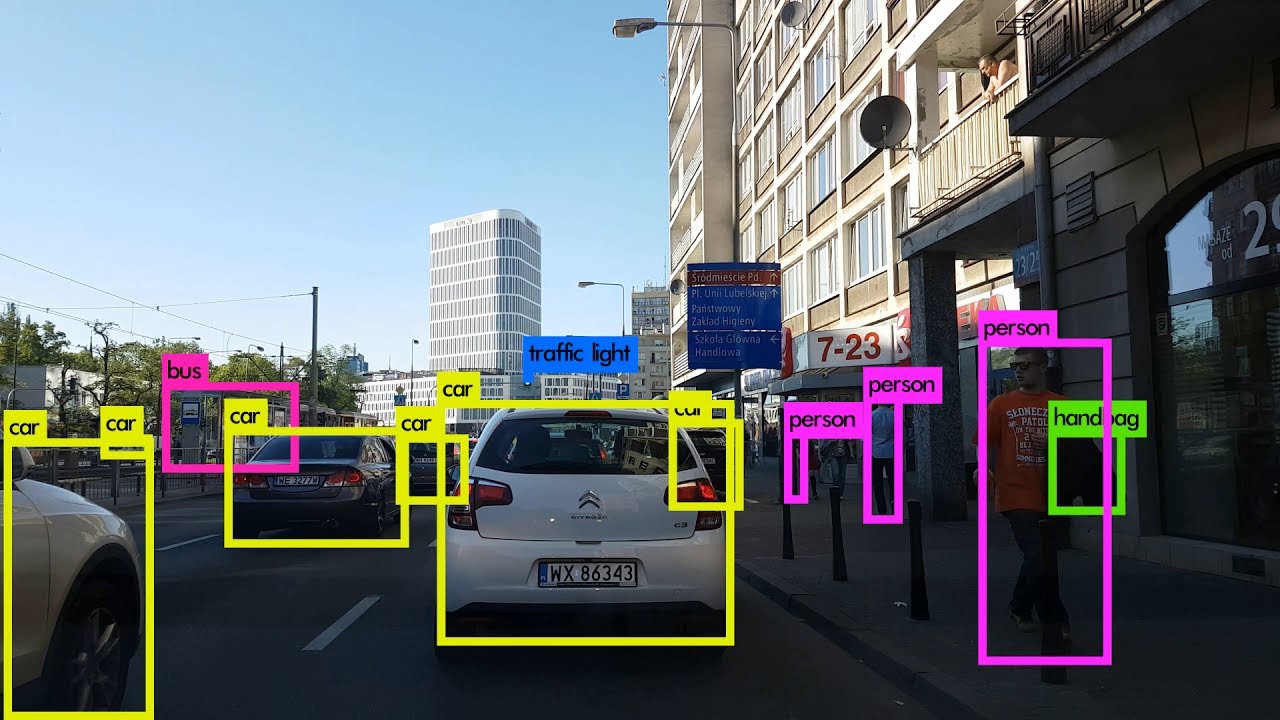
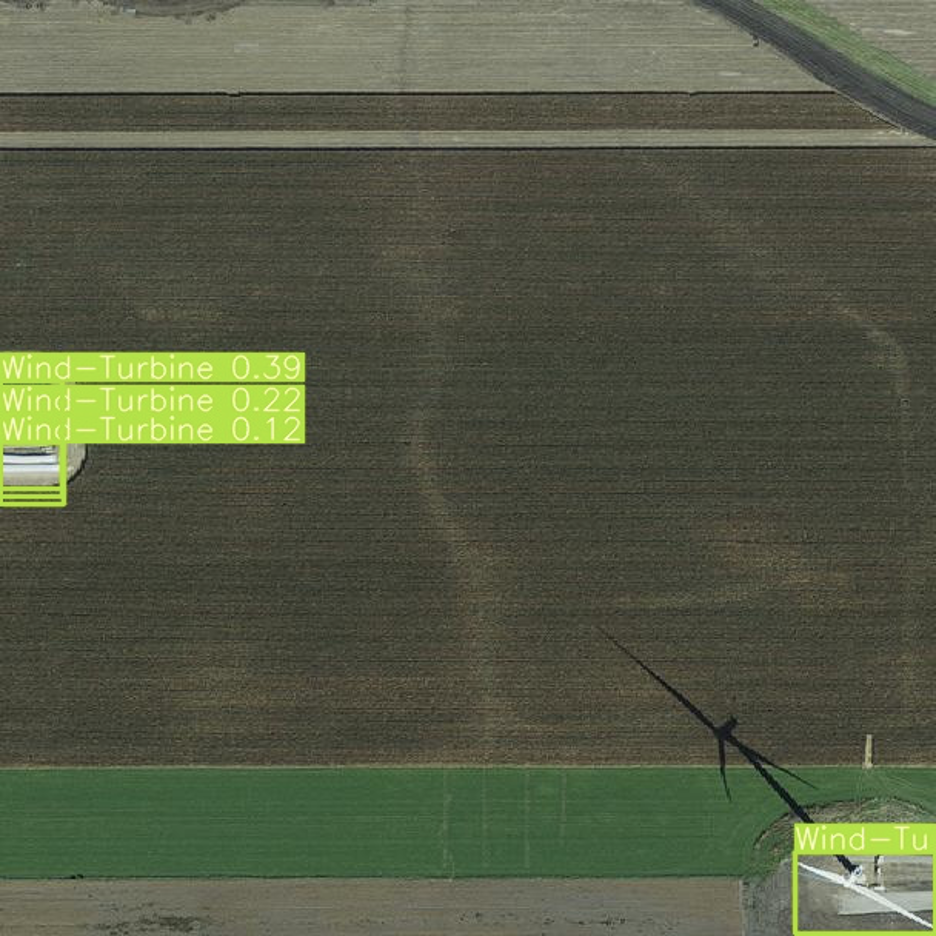
For this project, we focus on object detection, which is a combination of classification with object localization. The model analyzes images and predicts bounding boxes that surround each object within the image. It also classifies each object, producing a confidence score corresponding to the level of certainty of its prediction. In the image on the left, the model predicted that there were different objects represented by each of the boxes shown in green, yellow and pink. The model also predicted that the objects within these colored boxes were a handbag, a car, and a person respectively. The model learns how to predict these boxes and classifications based on examples shown to it. These examples have labels (the object’s class and the location of the bounding box within the image) that we collectively refer to as ground truth.
Applying Deep Learning to Overhead Imagery
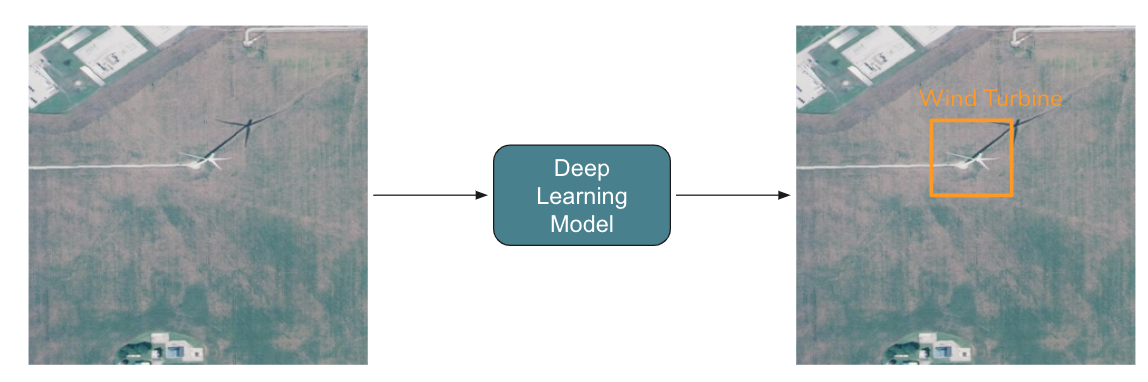
After training this model, we could apply it to a collection of overhead imagery to locate and classify energy
infrastructure across a whole region. While we could demonstrate this for any number of types of electricity
infrastructure, we use wind turbines because they are relatively homogeneous in appearance, unlike power plants,
for example, which come in many different configurations. Outside of size differences, there is little variation
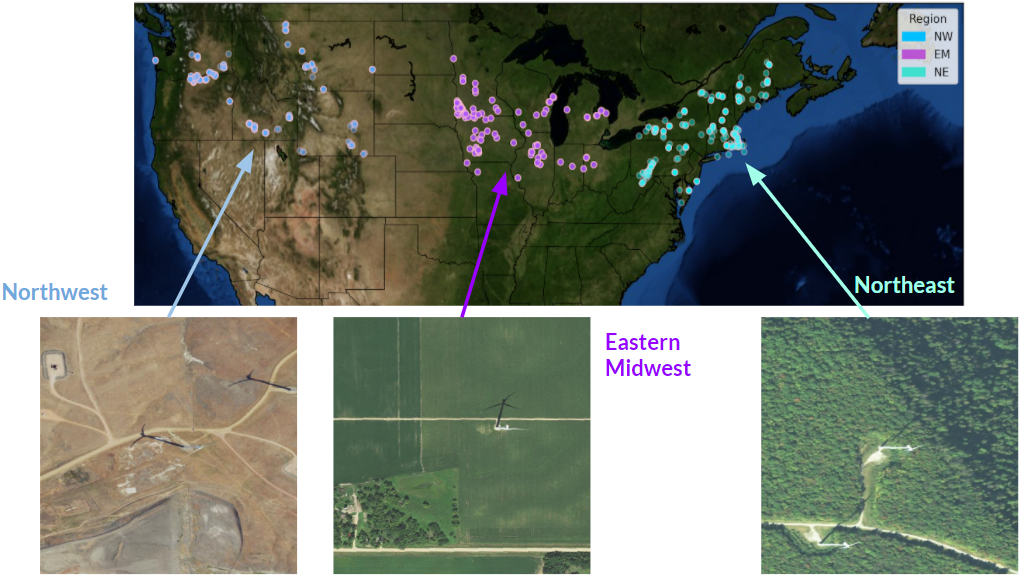
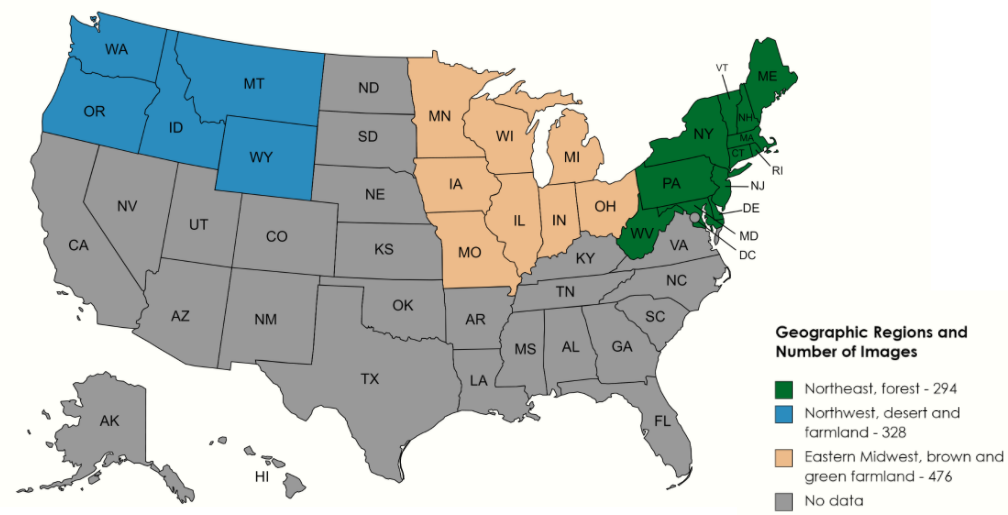
between types of wind turbines. We also start with data from within the US, because high resolution overhead imagery
data are readily available across the continental US.
After training this model, we could apply it to a collection of overhead imagery to locate and classify energy infrastructure across a whole region. While we could demonstrate this for any number of types of electricity infrastructure, we use wind turbines because they are relatively homogeneous in appearance, unlike power plants, for example, which come in many different configurations. Outside of size differences, there is little variation between types of wind turbines. We also start with data from within the US, because high resolution overhead imagery data are readily available across the continental US.
Challenges with Object Detection
Problem 1: Lack of labeled data for rare objects
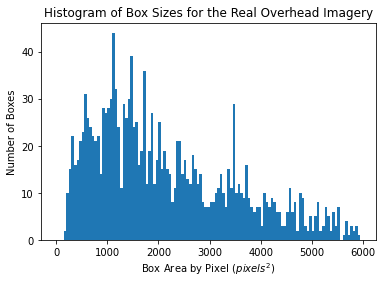
Object detection networks, like the one used in this work, are notorious for their "data hunger," requiring large amounts of annotated training data to perform well. For common infrastructure like buildings and roads, there is ample real-world data available to train such models. However, energy infrastructure is rare both in number and density, so collecting and annotating large amounts of satellite images manually is expensive and time consuming.
Problem 2: Domain adaptation
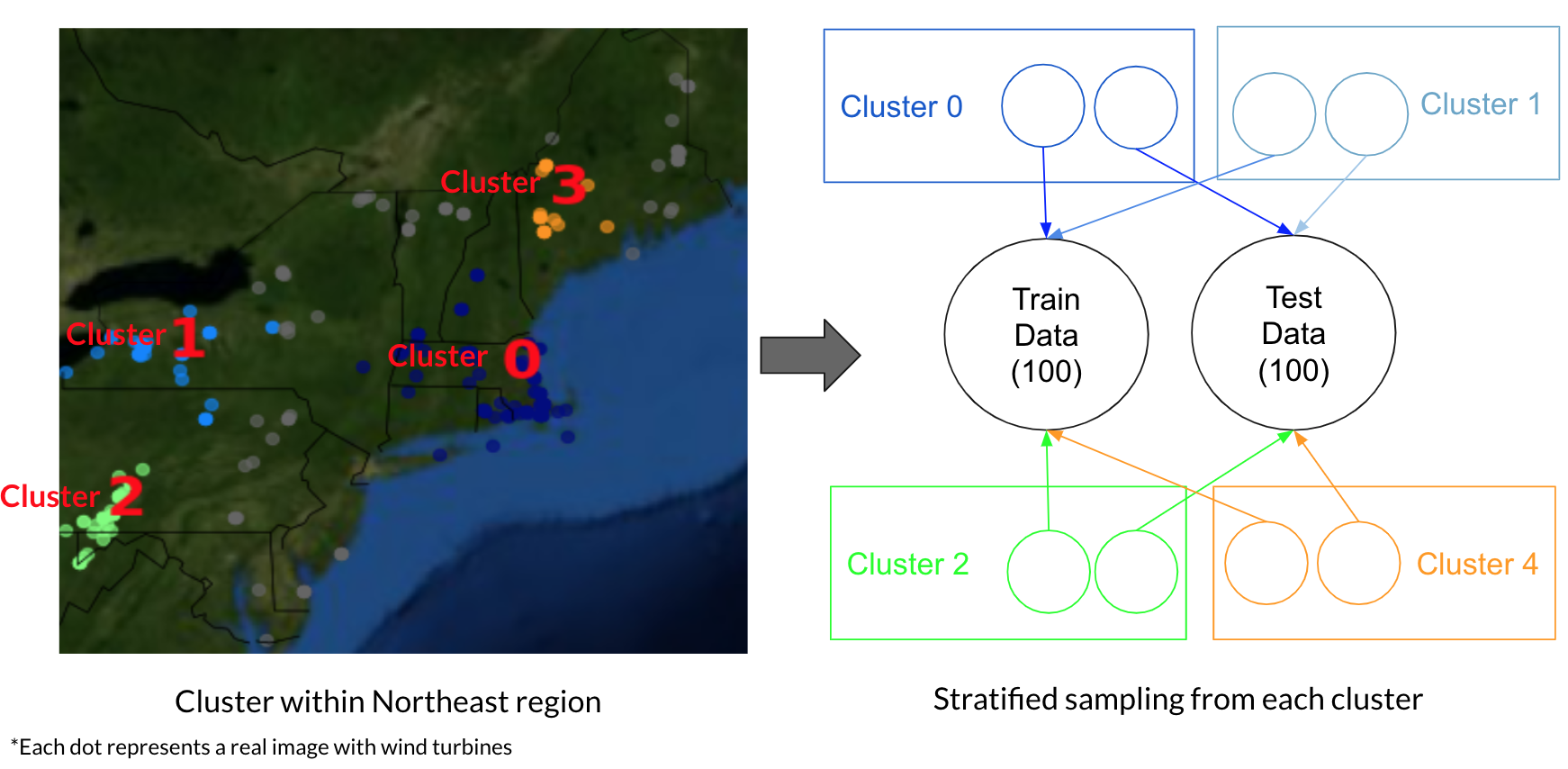
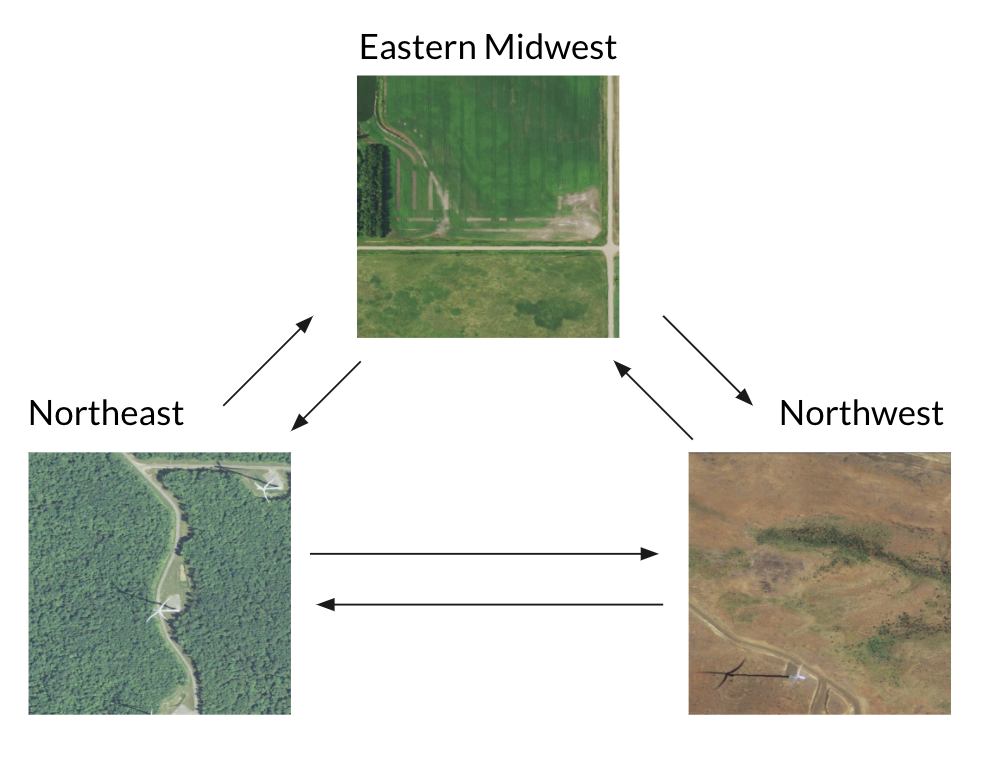
Typically our labeled training data are not from the same location as where we want to apply these techniques. However, object detection models poor performance on images that are from domians that are not similar to the ones that it has previously seen. In our case, this means the model will struggle when trying to apply it to new geographies and to different variations of styles of energy infrastructure.

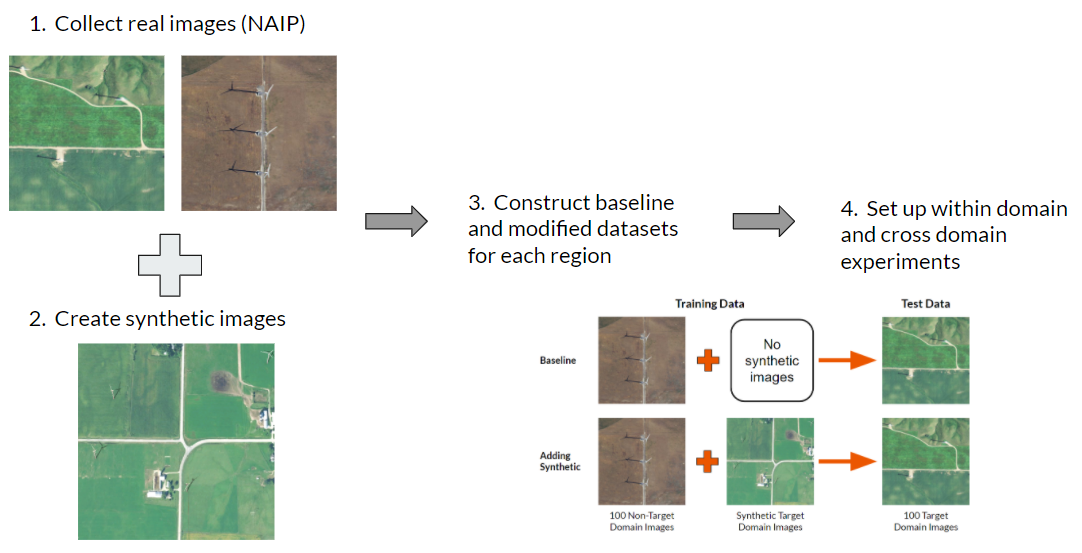
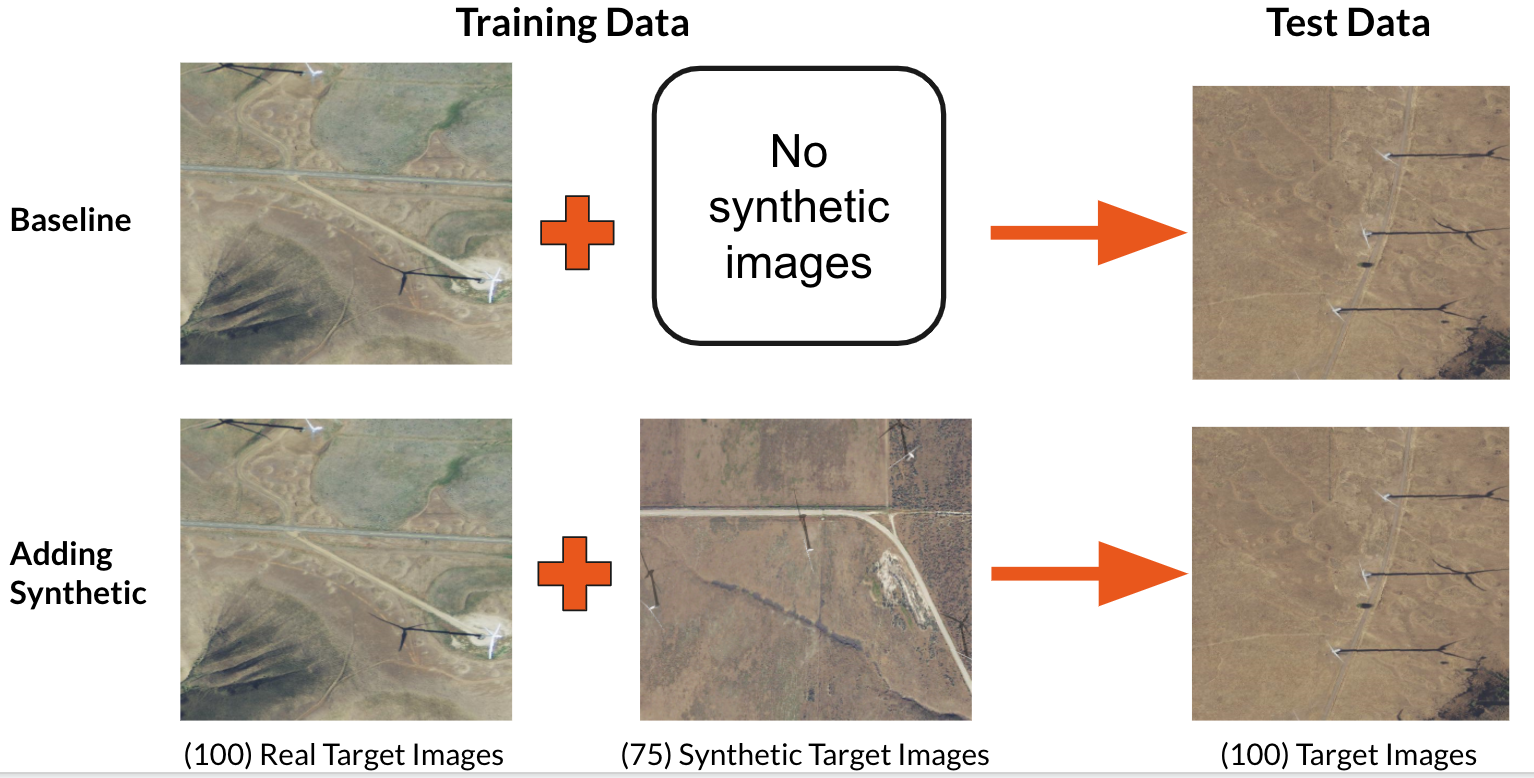
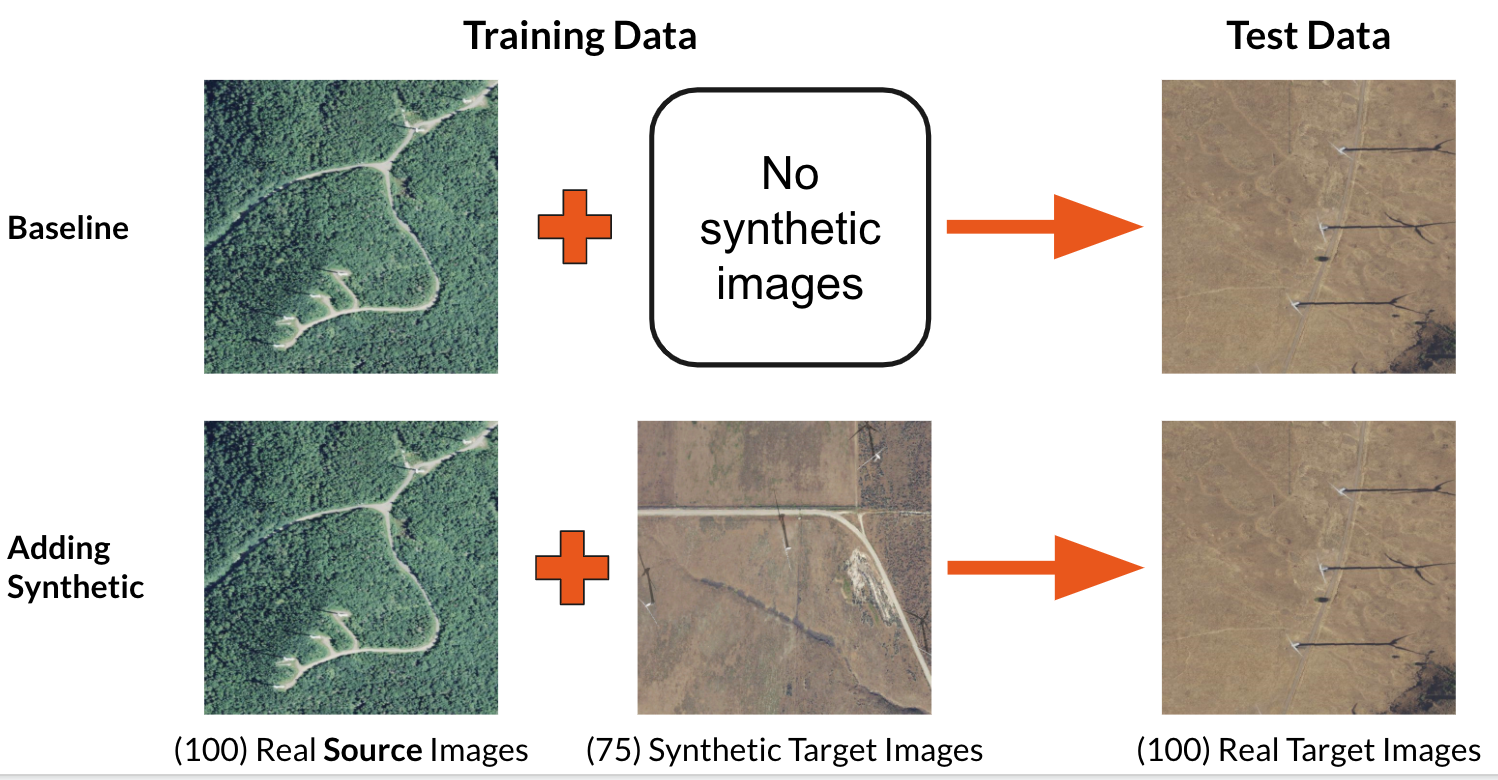
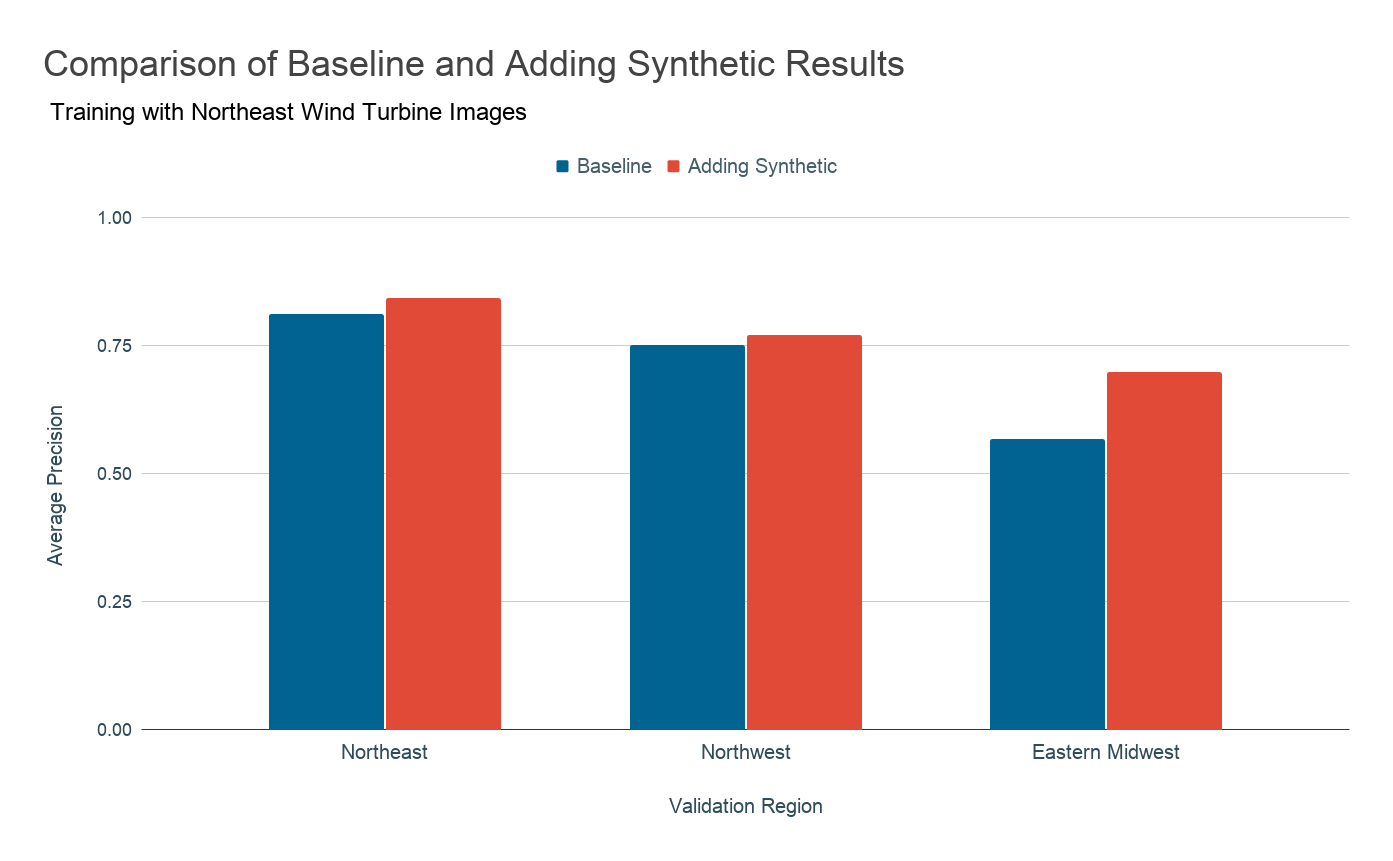
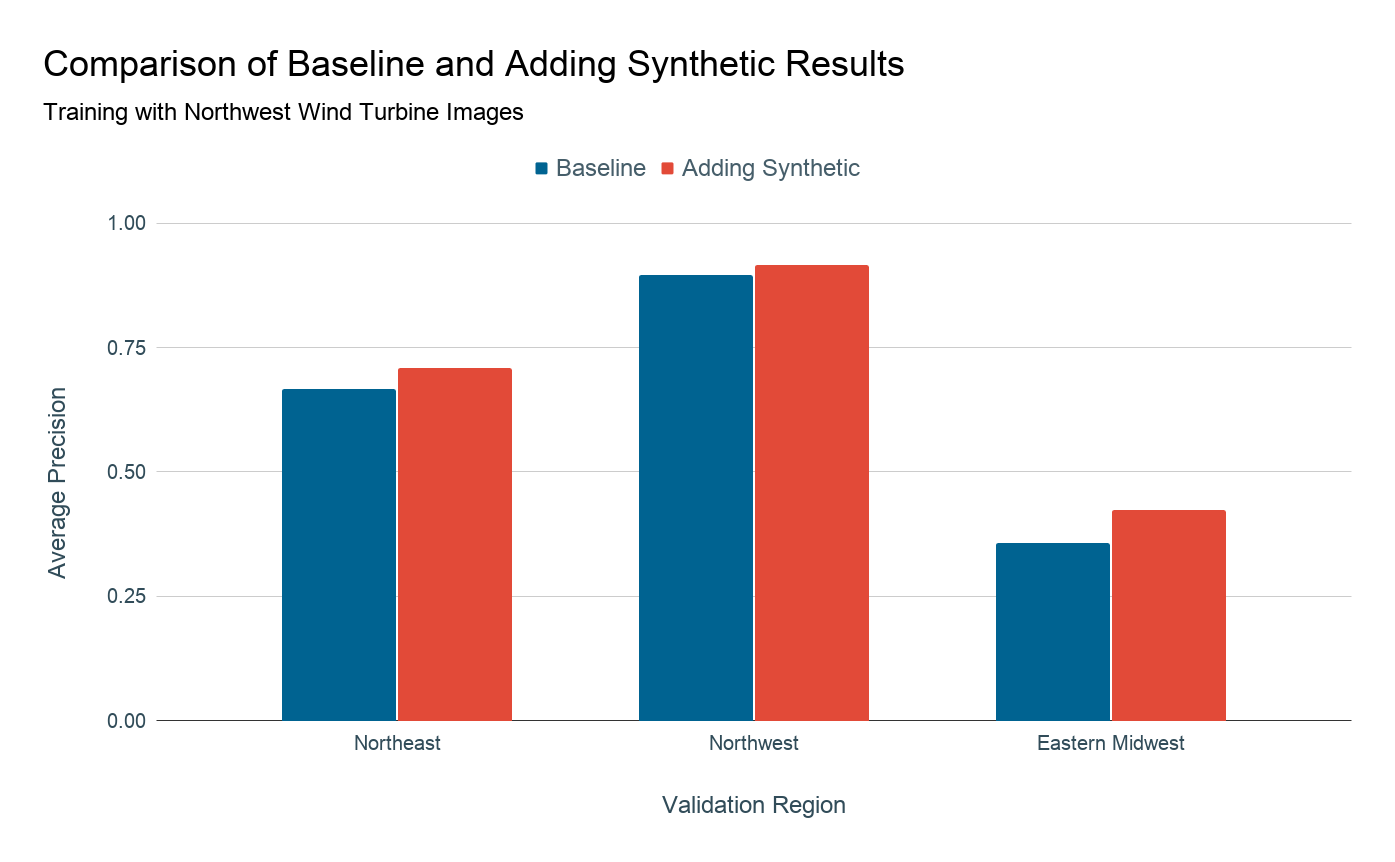
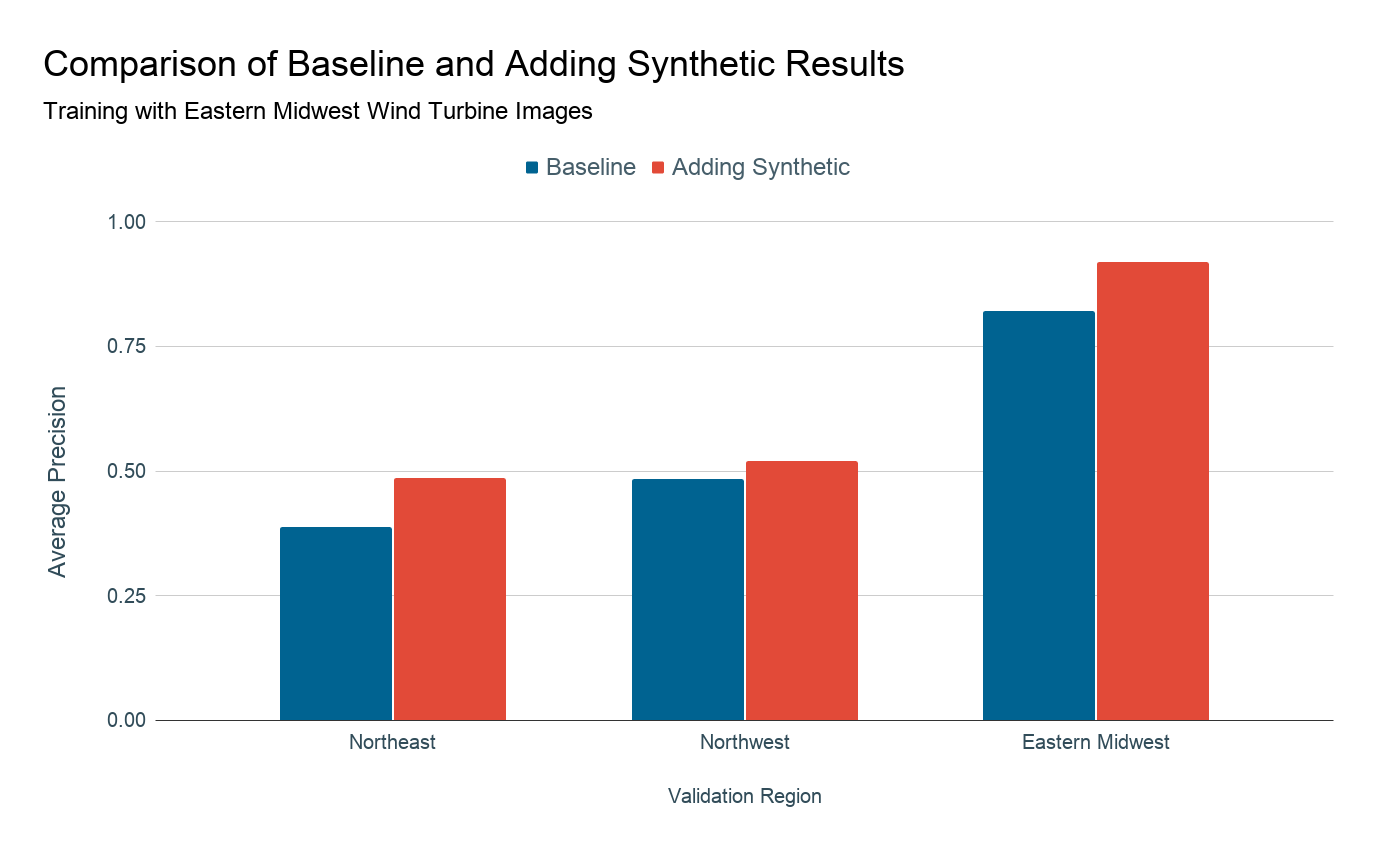
Proposed solution: synthetic imagery
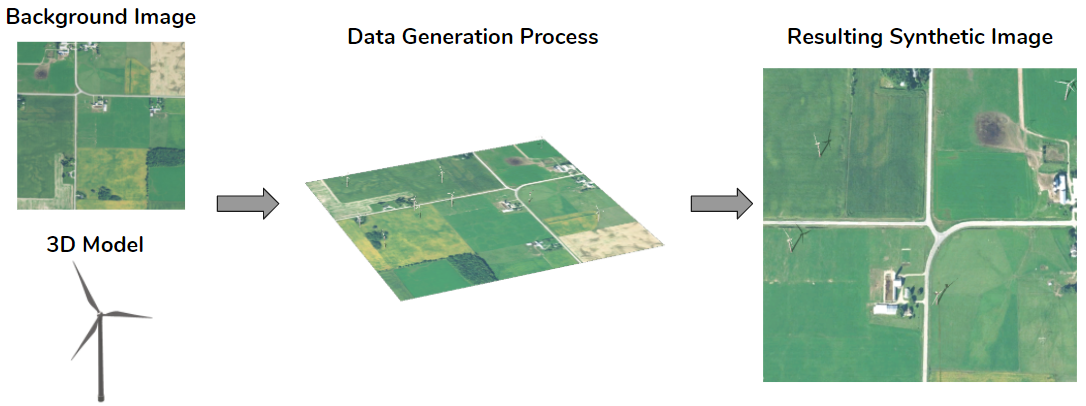
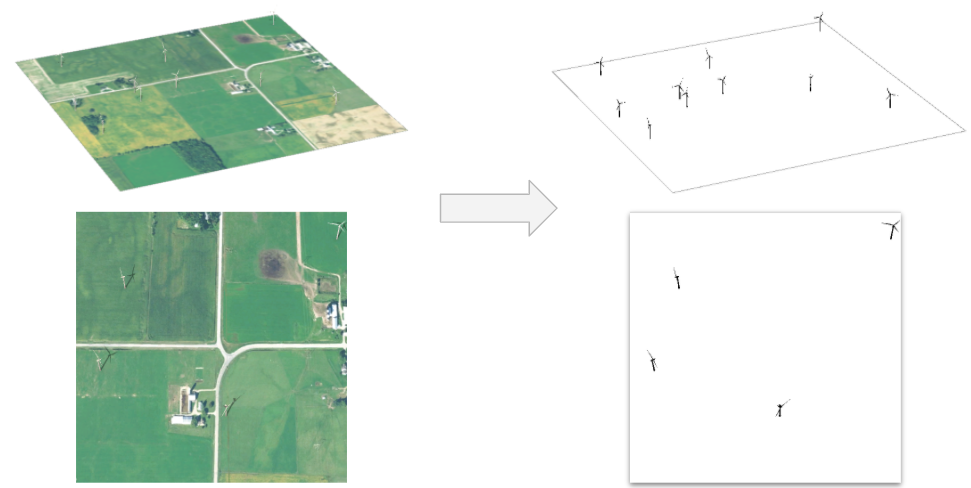
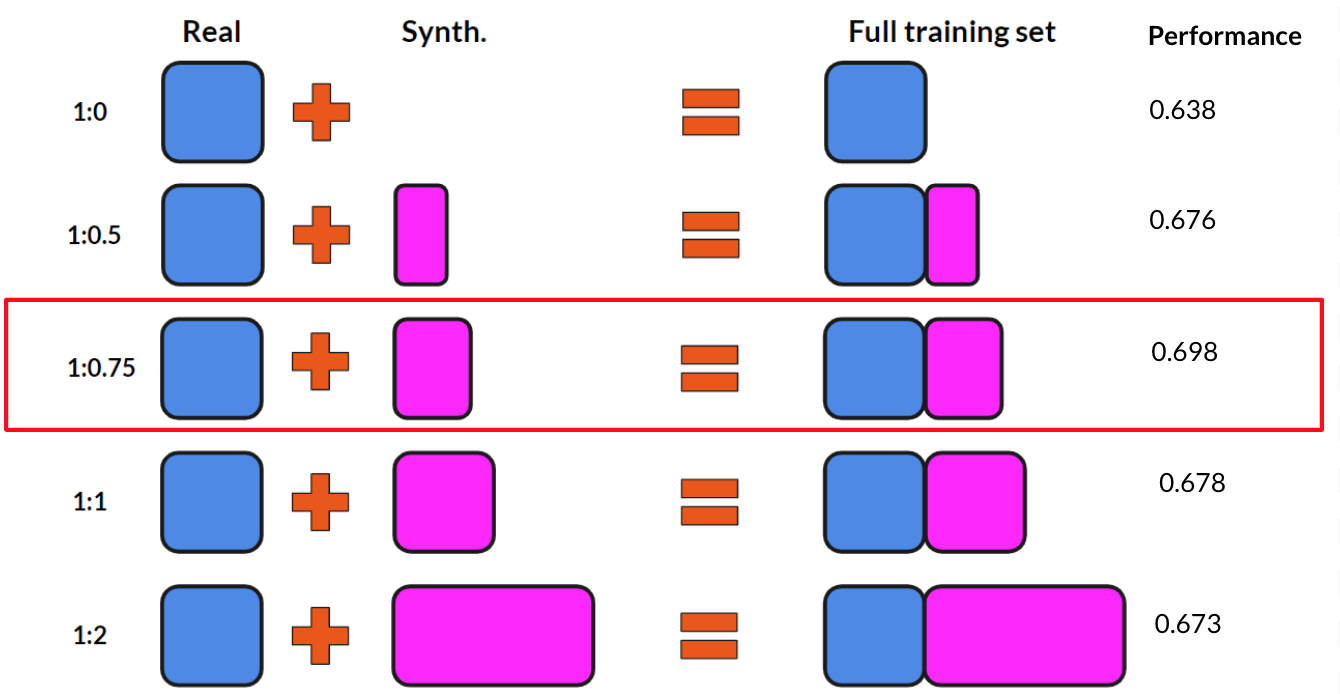
Since training data are difficult to collect, in this project we explore creating synthetic data to supplement the real data that are available. We do this by taking a real image without any energy infrastructure present and introducing a 3D model of an object of interest on top of that image as seen in the figure below. Then we position the camera in the overhead position and capture images in a manner that mimics the appearance of overhead imagery. Knowing where we placed the wind turbines in the synthetic image, we also generate ground truth labels for each of these images.
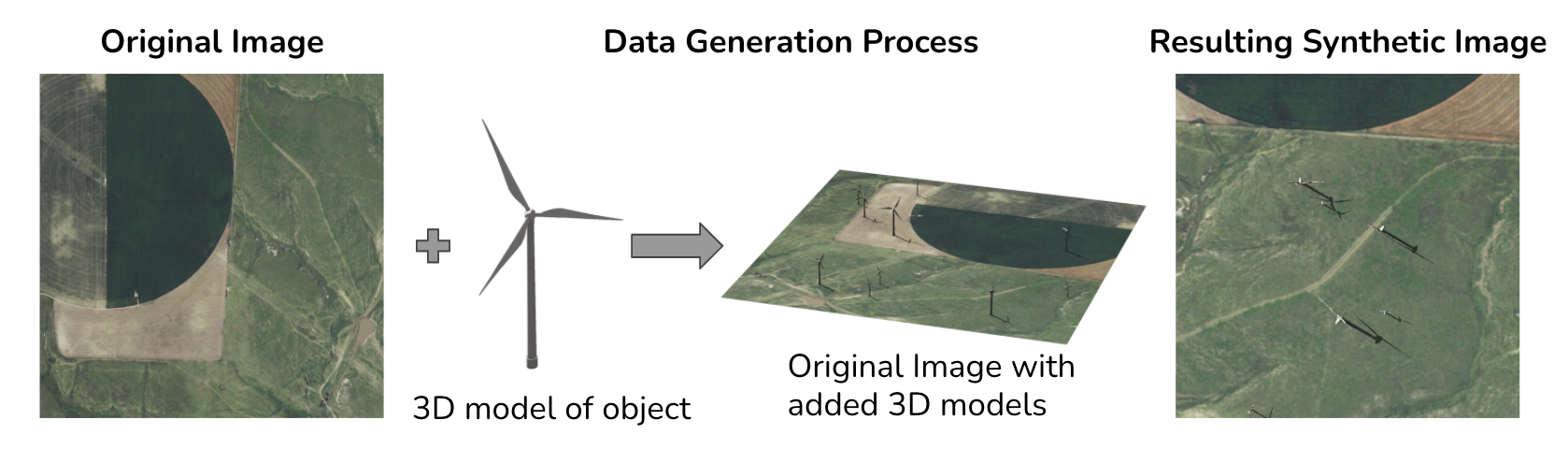
Previous work
For five years, the Duke Energy Data Analytics Lab has worked on developing deep learning models that identify energy infrastructure, with an end goal of generating maps of power systems and their characteristics that can aid policymakers in implementing effective electrification strategies. In 2015-16, researchers created a model that can detect solar photovoltaic arrays with high accuracy [2015-16 Bass Connections Team]. In 2018-19, this model was improved to identify different types of transmission and distribution energy infrastructures, including power lines and transmission towers [2018-19 Bass Connections Team]. Last year's project focused on increasing the adaptability of detection models across different geographies by creating realistic synthetic imagery [2019-20 Bass Connections Team]. In our project, we build upon this progress and try to improve the model's ability to detect rare objects in new, diverse locations.